5. Engineering and Architecture
In the black box
Data Flow Diagram
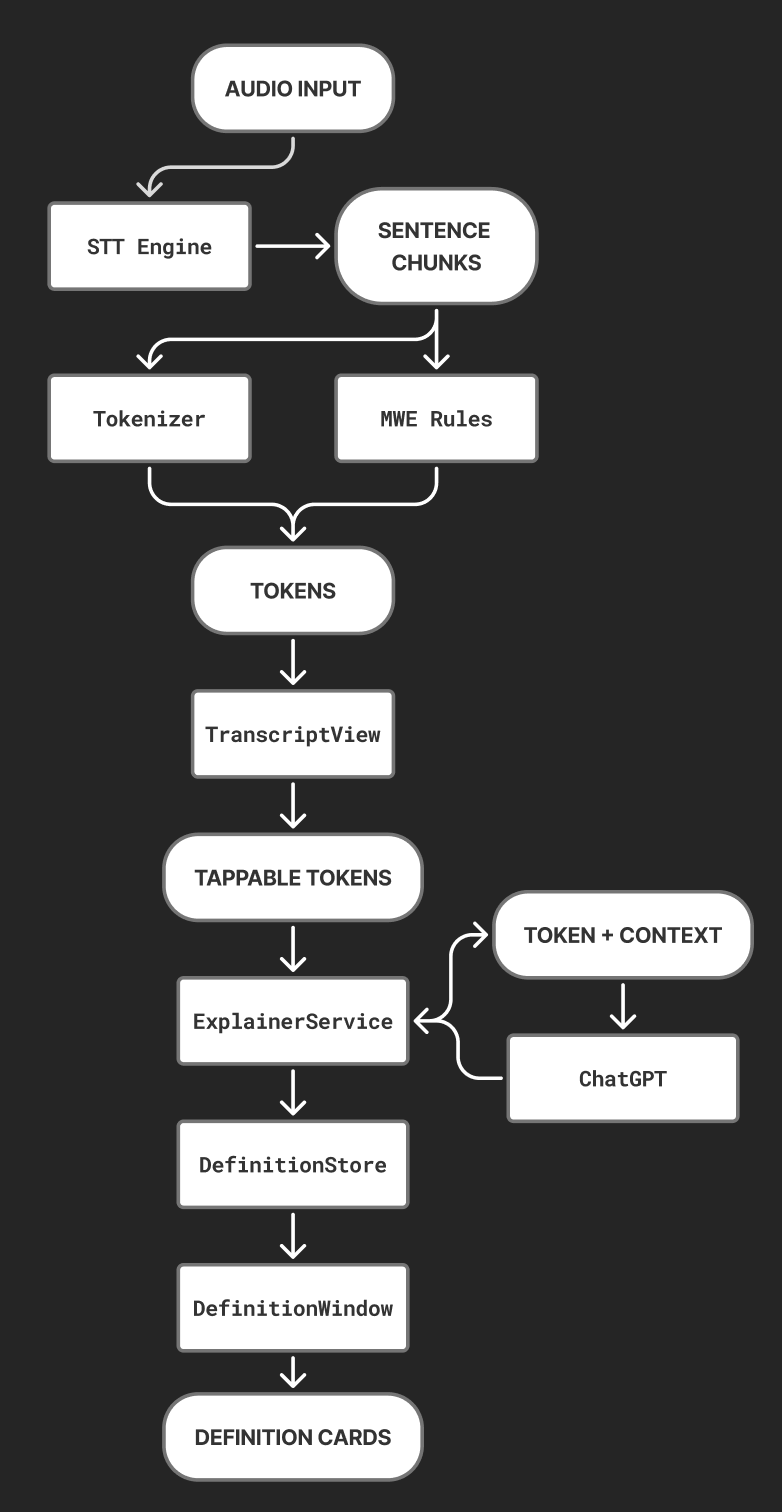
Debrieviate captures audio through the STT engine, which streams time-coded transcript chunks. These chunks are tokenized into words and multi-word expressions (e.g., South America) so each unit can be tapped. When the user taps a token, the app sends the term plus its surrounding context to the ExplainerService, which queries ChatGPT (or returns a cached result) to generate a short, plain-language definition. That definition is stored in DefinitionStore and rendered as a DefCard in the sidebar, keeping the user in flow without leaving the transcript.
Debrieviate captures audio through the STT engine, which streams time-coded transcript chunks. These chunks are tokenized into words and multi-word expressions (e.g., South America) so each unit can be tapped. When the user taps a token, the app sends the term plus its surrounding context to the ExplainerService, which queries ChatGPT (or returns a cached result) to generate a short, plain-language definition. That definition is stored in DefinitionStore and rendered as a DefCard in the sidebar, keeping the user in flow without leaving the transcript.
Modular Architecture
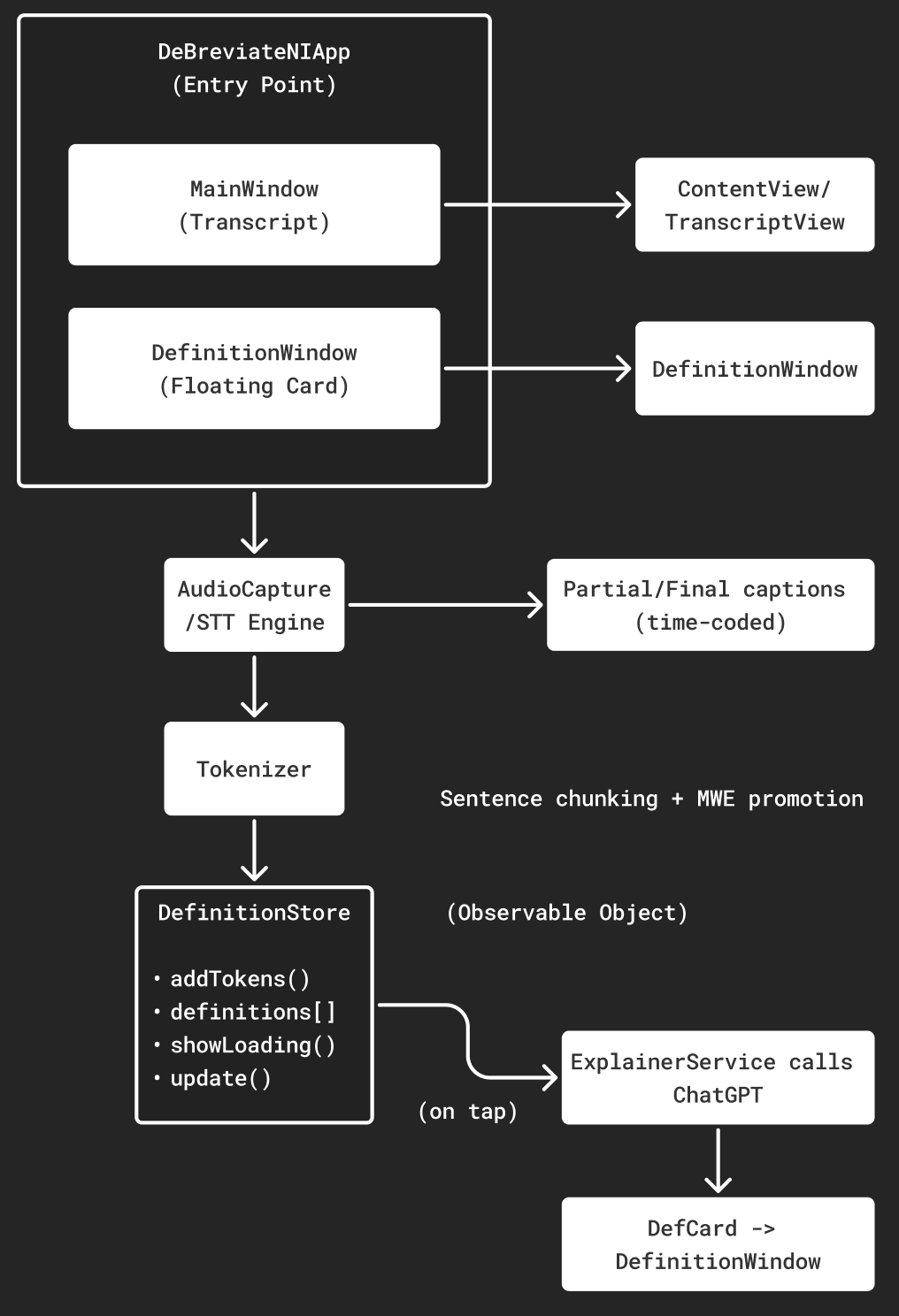
Debrieviate follows a clean modular structure. The DeBreviateNIApp entry point manages the main transcript window and floating definition window. User interactions in ContentView and TranscriptView trigger lookups, while DefinitionWindow displays returned results. All definitions are managed centrally in DefinitionStore, an ObservableObject that handles loading states and updates. Lookup requests are passed to the ExplainerService, which calls ChatGPT and returns a short definition. This separation of concerns keeps the app maintainable and testable, and extensible.
NLP Tokenization
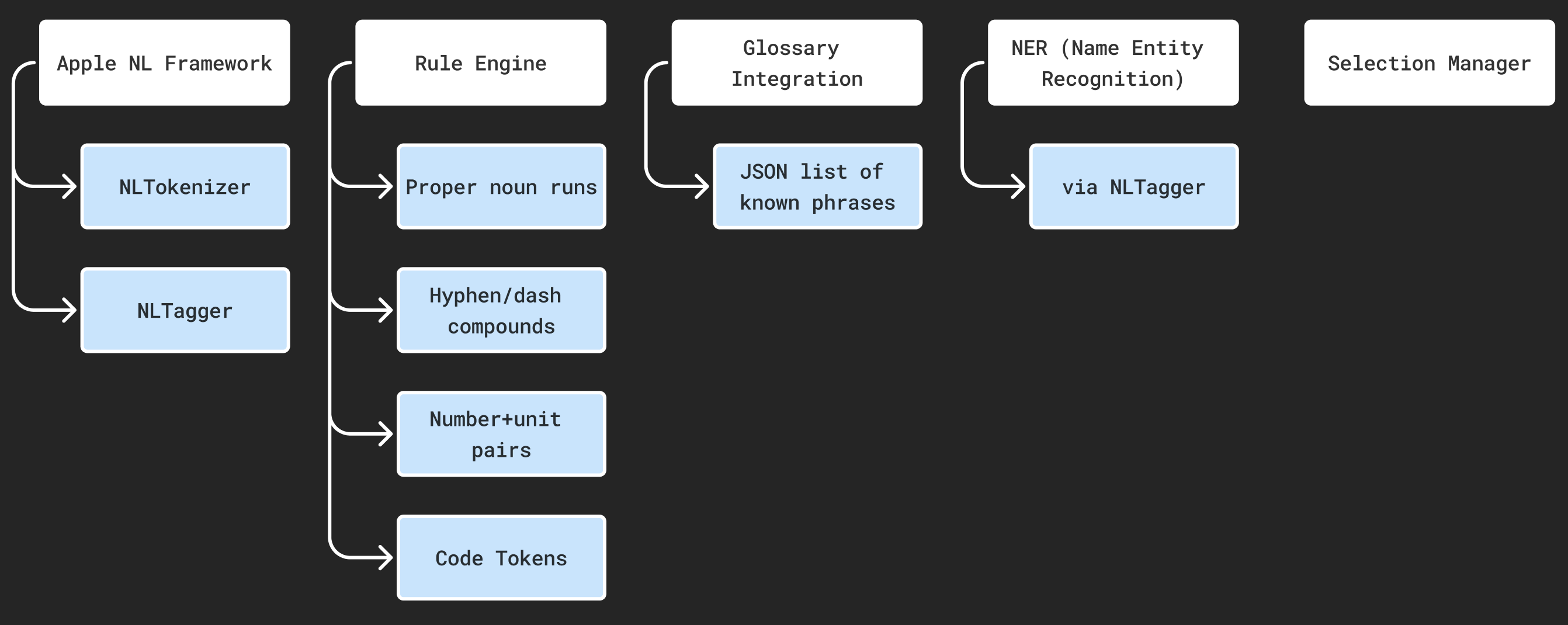
To make transcript interaction natural, we implemented a custom NLP tokenization pipeline instead of relying on simple whitespace splitting. The goal is to treat meaningful multi-word expressions as a single unit so users can request useful definitions (e.g., “Margaret Thatcher”, not “Margaret” + “Thatcher” separately).
The system combines:
Example Input:

Example output:

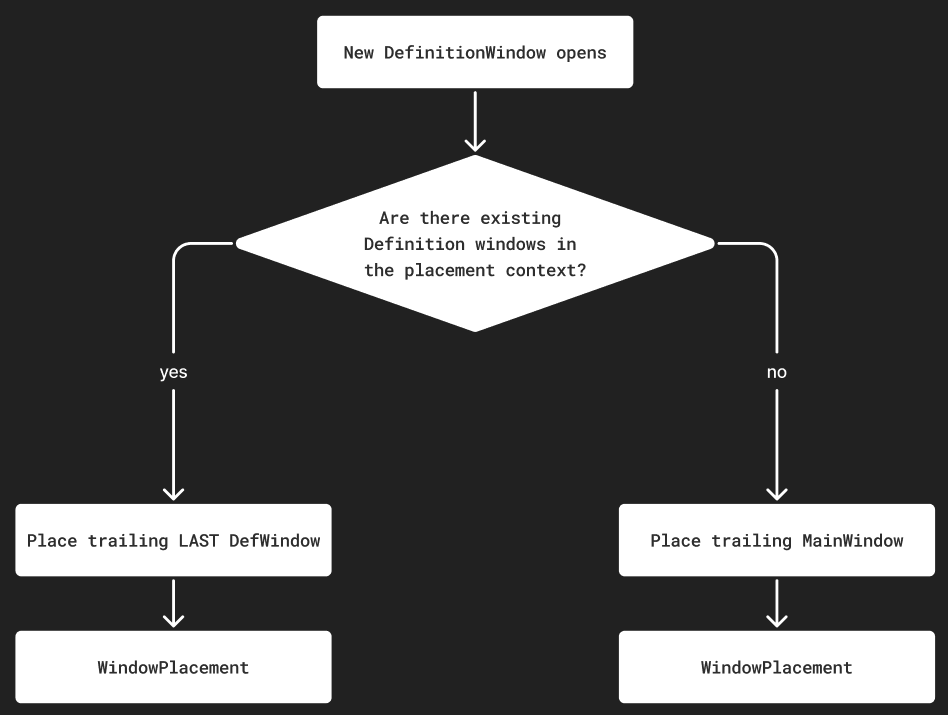
Window Placement Algorithm (Chained Trailing)
We designed a chained trailing algorithm to control how new definition windows appear in visionOS. Instead of overlapping on the transcript or stacking in one spot, each new window is placed to the side of the most recently opened one. The first definition window anchors beside the main transcript, while subsequent windows chain outward in a neat row.
This approach is highly User friendly:
-
It prevents clutter and overlap.
-
It creates a clear, organized flow of related definitions.
-
It mirrors the natural way people expand thoughts or annotations outward from a central idea.